
The Speech Synthesis API is an awesome tool provided by modern browsers. Introduced in 2014, it’s now widely adopted and available in Chrome, Firefox, Safari and Edge. IE is not supported.
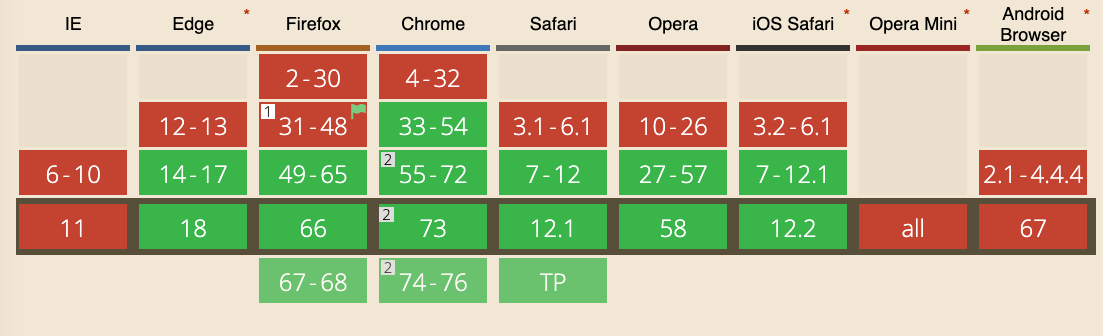
It’s part of the Web Speech API, along with the Speech Recognition API, although that is only currently supported, in experimental mode, on Chrome.
There is a long list of usage scenarios for this API. You can think of accessibility, first. And we have the opportunity to create interactive applications.
Currently on most browser we can make our scripts start speaking without being user activated. User activation is mandatory on iOS - the user must tap or do something to activate the audio play. This is quickly being moved to the browser as well - autoplay was deprecated in Chrome 70 due to abuse and removed in Chrome 71.
I personally used it to make a couple apps. The first one was a course signups monitoring tool. On launch days, I let it run in the background of my Mac and when a new person signs up, it just tells me. I don’t need to refresh a page or add email alerts. I was alerted thought the computer speakers, which is pretty cool.
Imagine the possibilities paired with IoT devices, too. Someone is near your door? You can detect the movement and the computer will tell you. Its application is however limited to the user activation requirement being imposed (we should thank everyone that abused this API, I think!)
Video of the demos
I made a video with me building all the demos in this lesson at https://www.youtube.com/watch?v=8cBUGEWAwwM:
Getting started
The speechSynthesis object available on the Window global object is your gateway to the Speech Synthesis API.
The most simple example of using the Speech Synthesis API stays on one line:
speechSynthesis.speak(new SpeechSynthesisUtterance('Hey'))
Copy and paste it in your browser console, and your computer should speak!
I made a little demo on Codepen. There is a button, once you click it, the computer will tell you “something”. You can find it at https://codepen.io/flaviocopes/pen/WWBvex and I embedded it here. Mind your audio volume, and click the button:
See the Pen SpeechSynthesis, say something by Flavio Copes (@flaviocopes) on CodePen.
Let’s see what this SpeechSynthesisUtterance object is, and how to use it.
The SpeechSynthesisUtterance object
The SpeechSynthesisUtterance object available on the global Window object represents a speech request.
In the example above we passed it a string. That’s the message the browser should read aloud.
Once you got the utterance object, you can perform some tweaks to edit the speech properties:
const utterance = new SpeechSynthesisUtterance('Hey')
Once you have the utterance object instance you can check the properties you can modify:
utterance.rate: set the speed, accepts between [0.1 - 10], defaults to 1utterance.pitch: set the pitch, accepts between [0 - 2], defaults to 1utterance.volume: sets the volume, accepts between [0 - 1], defaults to 1utterance.lang: set the language (values use a BCP 47 language tag, likeen-USorit-IT)utterance.text: instead of setting it in the constructor, you can pass it as a property. Text can be maximum 32767 charactersutterance.voice: sets the voice (more on this below)
Here is an example that alters the voice pitch, volume and rate:
const utterance = new SpeechSynthesisUtterance('Hey')
utterance.pitch = 1.5
utterance.volume = 0.5
utterance.rate = 8
speechSynthesis.speak(utterance)
How to change the voice
You are not limited to the default voice.
The browser has a different number of voices available.
To see the list, use this code:
console.log(`Voices #: ${speechSynthesis.getVoices().length}`)
speechSynthesis.getVoices().forEach((voice) => {
console.log(voice.name, voice.lang)
})
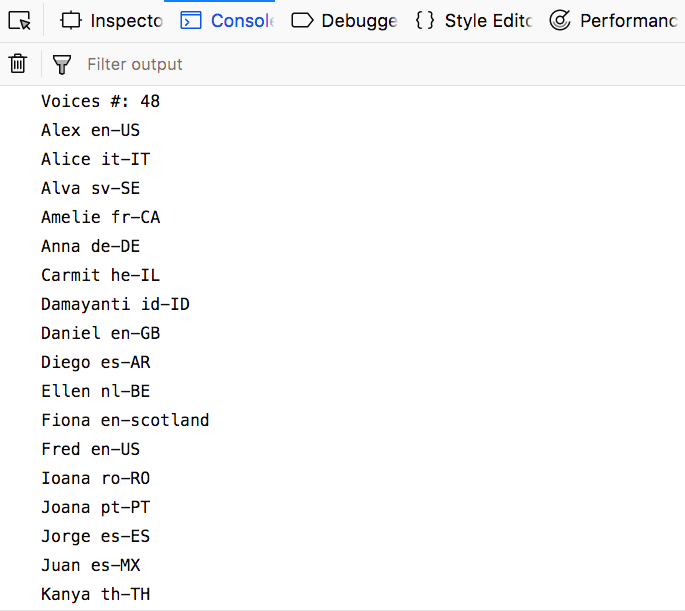
Here is one of the cross browser issues. The above code works in Firefox, Safari (and possibly Edge but I didn’t test it), but does not work in Chrome. Chrome requires the voices handling in a different way, and requires a callback that is called when the voices have been loaded:
const voiceschanged = () => {
console.log(`Voices #: ${speechSynthesis.getVoices().length}`)
speechSynthesis.getVoices().forEach((voice) => {
console.log(voice.name, voice.lang)
})
}
speechSynthesis.onvoiceschanged = voiceschanged
After the callback is called, we can access the list using speechSynthesis.getVoices().
As far as I know this difference is because Chrome - if there is a network connection - checks additional languages from the Google servers:
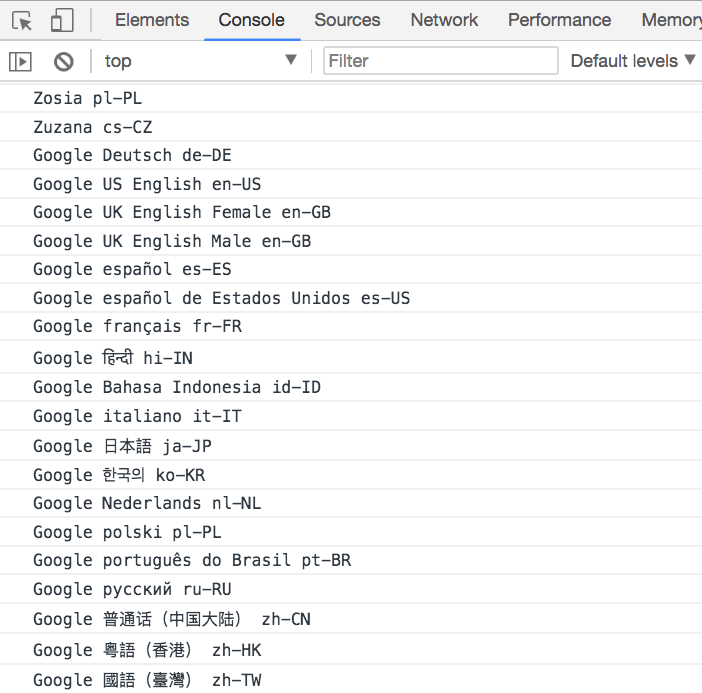
If there is no network connection, the number of languages available is the same as Firefox and Safari. The additional languages are available where the network is enabled, but the API works offline as well.
You can determine if a language is not available offline by checking the localService property of the SpeechSynthesisVoice object.
Cross browser implementation to get the language
Since we have this difference, we need a way to abstract it to use the API. This example does this abstraction:
const getVoices = () => {
return new Promise((resolve) => {
let voices = speechSynthesis.getVoices()
if (voices.length) {
resolve(voices)
return
}
speechSynthesis.onvoiceschanged = () => {
voices = speechSynthesis.getVoices()
resolve(voices)
}
})
}
const printVoicesList = async () => {
;(await getVoices()).forEach((voice) => {
console.log(voice.name, voice.lang)
})
}
printVoicesList()
I made a little demo that returns the voices available in your browser at https://codepen.io/flaviocopes/pen/dLEoQP:
See the Pen SpeechSynthesis, list voices by Flavio Copes (@flaviocopes) on CodePen.
Use a custom language
The default voice speaks in english.
You can use any language you want, by setting the utterance lang property:
let utterance = new SpeechSynthesisUtterance('Ciao')
utterance.lang = 'it-IT'
speechSynthesis.speak(utterance)
Use another voice
If there is more than one voice available, you might want to choose the other. For example the default italian voice is female, but maybe I want a male voice. That’s the second one we get from th voices list.
const lang = 'it-IT'
const voiceIndex = 1
const speak = async (text) => {
if (!speechSynthesis) {
return
}
const message = new SpeechSynthesisUtterance(text)
message.voice = await chooseVoice()
speechSynthesis.speak(message)
}
const getVoices = () => {
return new Promise((resolve) => {
let voices = speechSynthesis.getVoices()
if (voices.length) {
resolve(voices)
return
}
speechSynthesis.onvoiceschanged = () => {
voices = speechSynthesis.getVoices()
resolve(voices)
}
})
}
const chooseVoice = async () => {
const voices = (await getVoices()).filter((voice) => voice.lang == lang)
return new Promise((resolve) => {
resolve(voices[voiceIndex])
})
}
speak('Ciao')
I made a little demo on this on Codepen, at https://codepen.io/flaviocopes/pen/BEeNpz.
I embedded it here below:
See the Pen SpeechSynthesis, choose voices by Flavio Copes (@flaviocopes) on CodePen.
You can change the language choosing from a list of 4 I added (there are many more). Also, for every language you can pick one of the first 4 voices. A language might not have more than 1 or 2 voices, and in that case it will fallback to english.
Values for the language
Those are some examples of the languages you can use:
- Arabic (Saudi Arabia) ➡️
ar-SA - Chinese (China) ➡️
zh-CN - Chinese (Hong Kong SAR China) ➡️
zh-HK - Chinese (Taiwan) ➡️
zh-TW - Czech (Czech Republic) ➡️
cs-CZ - Danish (Denmark) ➡️
da-DK - Dutch (Belgium) ➡️
nl-BE - Dutch (Netherlands) ➡️
nl-NL - English (Australia) ➡️
en-AU - English (Ireland) ➡️
en-IE - English (South Africa) ➡️
en-ZA - English (United Kingdom) ➡️
en-GB - English (United States) ➡️
en-US - Finnish (Finland) ➡️
fi-FI - French (Canada) ➡️
fr-CA - French (France) ➡️
fr-FR - German (Germany) ➡️
de-DE - Greek (Greece) ➡️
el-GR - Hindi (India) ➡️
hi-IN - Hungarian (Hungary) ➡️
hu-HU - Indonesian (Indonesia) ➡️
id-ID - Italian (Italy) ➡️
it-IT - Japanese (Japan) ➡️
ja-JP - Korean (South Korea) ➡️
ko-KR - Norwegian (Norway) ➡️
no-NO - Polish (Poland) ➡️
pl-PL - Portuguese (Brazil) ➡️
pt-BR - Portuguese (Portugal) ➡️
pt-PT - Romanian (Romania) ➡️
ro-RO - Russian (Russia) ➡️
ru-RU - Slovak (Slovakia) ➡️
sk-SK - Spanish (Mexico) ➡️
es-MX - Spanish (Spain) ➡️
es-ES - Swedish (Sweden) ➡️
sv-SE - Thai (Thailand) ➡️
th-TH - Turkish (Turkey) ➡️
tr-TR
Multiple voices at the same time
You can’t create two instances of SpeechSynthesisUtterance and make them play the audio simultaneously.
Any subsequent attempt to make a voice play after the first one is created will be queued in the utterance queue.
Here is a simple example. You click the buttons as fast as you want, but the text will play in series one after the other: https://codepen.io/flaviocopes/pen/MRdYqJ
See the Pen SpeechSynthesis, say multiple things by Flavio Copes (@flaviocopes) on CodePen.